1. 사용 계기
프로젝트를 하면서 open source나 데브코스 1기 기수의 github repo 코드를 보고 이해해야 하는 상황이 꽤 많았다. 그 과정에서 코드를 이해하는데 시간과 노력이 많이 들어갔었다. 잘 모르는 부분이 있으면 gpt한테 물어보곤 했는데, 코드를 하나하나 복사해서 붙여넣는 과정이 번거롭고 노가다성이 짙다 보니 자동화 해보고싶은데? 라는 생각이 들기 시작했다.
처음엔 openai api를 사용해보려고 했지만, 돈이 부족한 취준생이라 오픈소스를 찾기 시작했고 그 과정에서 로컬 모델을 위한 서비스? 프레임워크? ollama를 알게 되었다. 한국어 자료로는 테디노트 유튜브 영상을 많이 찾아봤다.
(llama3를 사용한 줄 알았는데, 지금 정리하면서 찾아보니까 upstage가 제공한 모델을 한국어로 파인튜닝을 한 모델인 것 같다.)
로컬에 clone해둔 github repo의 코드 파일을 input으로 주고, 해당 코드 파일에 대한 간략한 wiki를 작성하는 것을 목표로 미니 프로젝트를 진행해보았다.
- 참고 링크들
upstage 모델
yanolja에서 파인튜닝 한 모델
yanolja 모델의 gguf 버전
해당 모델을 사용한 튜토리얼 영상 by 테디노트
google colab에서 ngrok을 사용해 llm 모델 서버 실행하기
2. 환경 설정
1) llm 모델 서버 환경 설정
CPU - venv 사용
사용 모델

모델 실행
1 2 3# venv 실행 후 진행 ollama serve # serve 이후 터미널 창을 추가로 켜줘야 함1ollama pull llama3HuggingFace를 통해 다운받은 .gguf 형태의 모델은 Modelfile 작성후 빌드하는 과정이 필요함
1ollama create EEVE-Korean-10.8B -f EEVE-Korean-Instruct-10.8B-v1.0/Modelfile
GPU - google colab 노트북 사용
내 컴퓨터 GPU를 사용하는 과정에서 CUDA 설치 등 번거로운 부분이 좀 있어서, 고민하다가 colab에서 제공하는 GPU를 사용해보기로 했다.
colab에서 모델 서버를 실행하고, 로컬에서 접속하는 방식으로 구현이 가능하다.
역시 테디노트님의 영상을 많이 참고했고, colab에서 모델 실행하는 방법은
판다스 스튜디오 유튜브영상을 참고했다. colab 노트북 파일실행 과정 - colab 노트북 참고
- ngrok 사이트에서 auth token을 발급받는다.

- 토큰 입력 후 아래의 두 블럭을 실행한다.
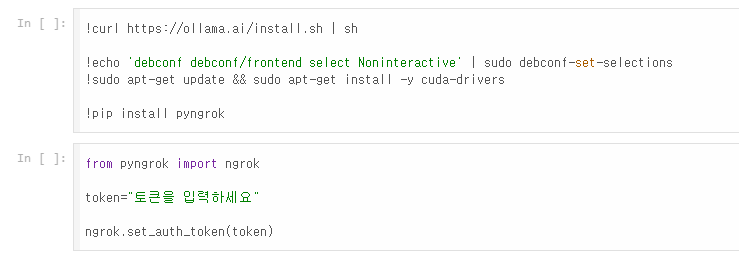
- 직접 모델과 모델파일을 colab에 업로드하거나, hugging face cli를 활용해 다운받는다.
나는 hugging face cli로 다운받도록 코드를 작성했고, 모델파일은 로컬에서 작성 후 업로드했다.

- 코드 구동 시 ngrok url을 확인할 수 있음
- 기존 코드에서 host를 해당 url으로 변경 후 실행 : 기존과 비교할 수 없이 빠른 속도로 실행
- ngrok 사이트에서 auth token을 발급받는다.
2) python 코드 실행 환경 (venv)
- 이전에 진행한 프로젝트의 python 파일에 대해 wiki를 생성하도록 코드를 작성했다.
- 똑같이 환경을 위한 venv를 만들어 필요한 라이브러리를 설치했고 (ollama 등), 코드는 gpt의 도움을 받았다. 원래는 처음부터 직접 해보려고 했지만 그럼 너무 오래걸릴 것 같아서 일단 실행한 후에 코드를 분석하고 수정해나가면서 복습하기로 했다.
- code
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86import os import logging import ollama import httpx # 로그 설정 logging.basicConfig(level=logging.INFO) # HTTP 클라이언트 설정 timeout = httpx.Timeout(120.0) # 타임아웃 설정 (예: 120초) # 코드 파일 읽기 def read_code_files(local_path): code_files = [] for root, dirs, files in os.walk(local_path): for file in files: if file.endswith(".py"): # Python 파일만 선택 with open(os.path.join(root, file), "r") as f: code_files.append((file, f.read())) return code_files # 코드 설명 생성 (스트리밍 방식) def generate_explanation(code): try: logging.info( f"Generating explanation for code:\n{code[:60]}..." ) # 첫 60자 로깅 # Ollama 클라이언트 설정 client = ollama.Client(host="http://localhost:11434") # 로컬 서버 URL과 포트 확인 # colab GPU 사용 버전 # client = ollama.Client(host="{ngrok url}") stream = client.chat( model="{사용할 model 이름}", messages=[ { "role": "user", "content": f"Explain the following code in detail wiki format, and translate it in korean :\n{code}", }, ], stream=True, ) explanation = "" for chunk in stream: explanation += chunk["message"]["content"] print(chunk["message"]["content"], end="", flush=True) return explanation except httpx.RequestError as e: logging.error(f"Request error: {e}") return "Error generating explanation due to request error." except httpx.TimeoutException: logging.error("Request timed out") return "Error generating explanation due to timeout." except Exception as e: logging.error(f"Error generating explanation: {e}") return "Error generating explanation." # Wiki 생성 def generate_wiki(code_files): wiki_content = "" for file_name, code in code_files[:1]: explanation = generate_explanation(code) wiki_content += f"## {file_name}\n\n{explanation}\n\n" return wiki_content if __name__ == "__main__": # # 이미 클론된 로컬 Git 리포지토리 경로 local_path = os.getcwd() code_files = read_code_files(f"{local_path}") wiki_content = generate_wiki(code_files) # Wiki 파일 저장 with open("wiki.md", "w") as wiki_file: wiki_file.write(wiki_content) print("Wiki generated and saved to wiki.md")
3. 결과 화면
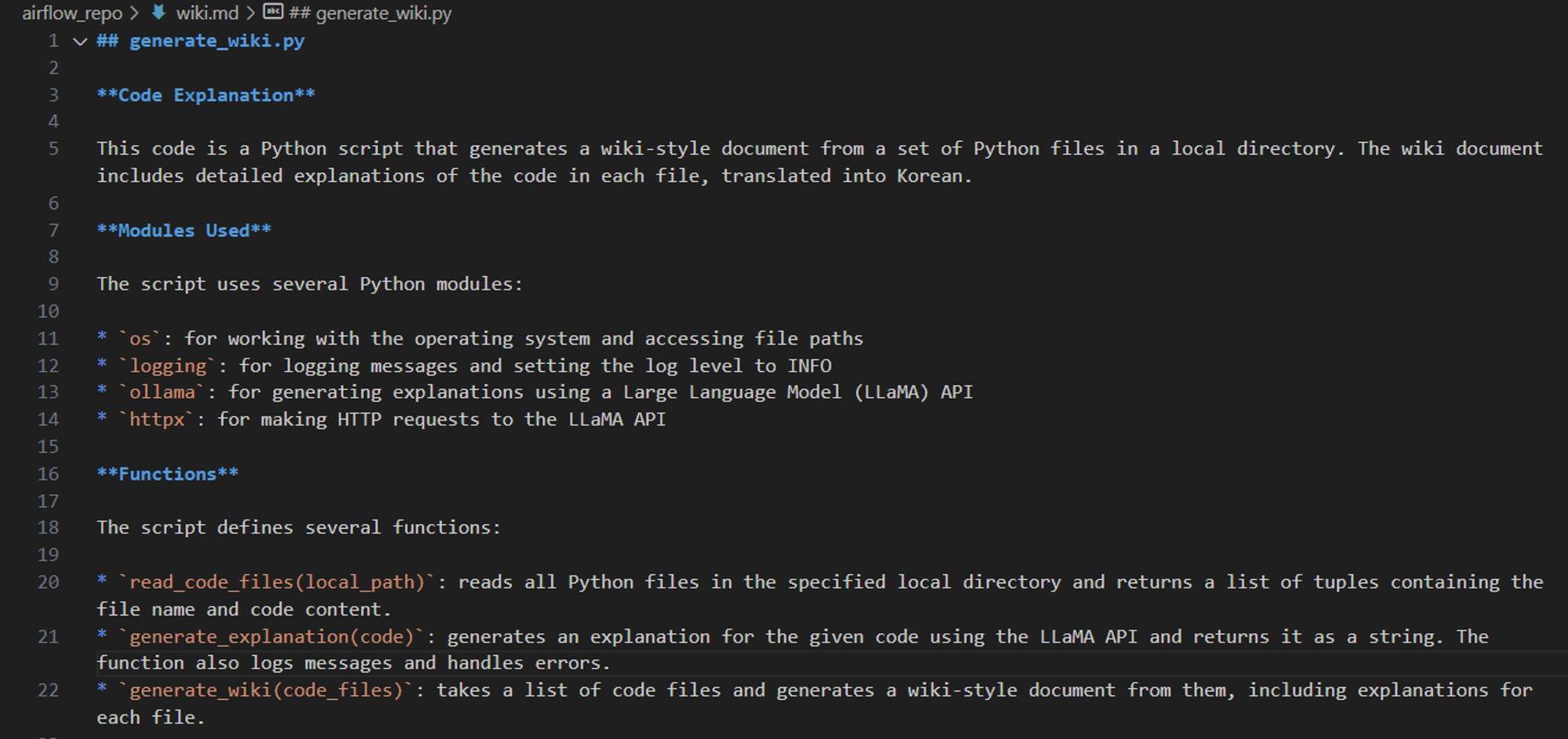

- pdf 요약 시도 시 결과 (분할해 전달한 경우)

4. Q&A
발표했을 당시에 받았던 Q&A 및 추가 고려할 점을 적어본다.
(추가적으로 생각나는 게 있으면 이 부분에 추가해서 더 적을 것!)
답변 구조 설정 방법
ollama 모델이 실제 사용되는 서비스?
pdf, word 파일도 가능? → 가능
- OCR 거쳐서 텍스트가 인식 된 파일일경우는 바로 가능
- 안되는 경우는 텍스트 인식이 제대로 안되거나, encoding 등의 문제
CPU/GPU 각각 속도 비교하는 코드 작성해보기
RAG에 대해 더 알아보기